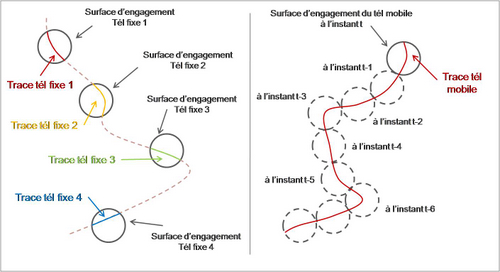
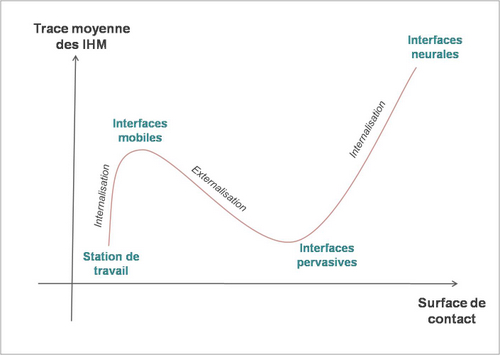
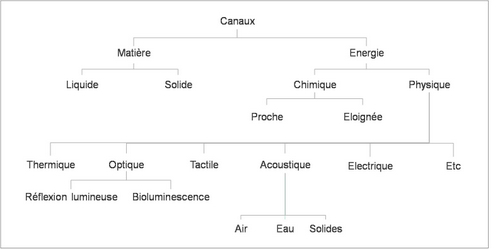
La vision transhumaniste prévoit la possibilité dans un futur proche de télécharger son cerveau sur le réseau. Vision à la fois séduisante et effrayante mais qui n’est pas sans implications quant à la nature de l’intelligence ainsi transférée.
Commençons par voir le cerveau comme une boite noire qui prend des intrants et produits des extrants. Numériser le cerveau de manière fidèle consiste alors à pouvoir produire pour tout intrant le même extrant qui serait produit par le cerveau « réel ». Passons sur le fait qu’une telle preuve est impossible à établir, et intéressons nous à la manière de produire une version digitale du cerveau. Pour produire les mêmes extrants à partir d’intrants donnés il faut être capable de reproduire les règles du fonctionnement du cerveau. Les transhumanistes envisagent qu’avec les progrès de la science/médecine il soit possible d’extraire ces règles (qui seraient spécifiques à chaque individu) et de se libérer ainsi de la matérialité du cerveau.
Malgré les difficultés que cela représente, admettons. On réussirait donc à créer un modèle numérique du cerveau dont les réactions seraient strictement équivalentes à celui sur lequel il a été copié. Cela suffit-il à conclure à la réussite de l’entreprise ? Heureusement/Malheureusement loin de là !
En mathématique irait-on conclure que deux courbes ayant un point commun sont identique ? Non elles ont seulement un point commun. En génétique, deux phénotypes exactement identiques peuvent disposer de génotypes différents, du fait de ce qu’on appelle la neutralité. Par exemple certaines mutations génétiques sont dites neutres parce que plusieurs codons peuvent coder le même acide aminé. Seulement l’étude de la neutralité montre que deux génotypes ayant la même expression phénotypique à un temps T n’ont plus nécessairement la même expression à un temps T+n.
Dans notre cas notre disposons de deux représentations, l’une analogique l’autre digitale, s’exprimant de la même manière à un temps T. Expression que j’appellerai « intelligence ». Toute la question est de savoir si intelligence analogique et intelligence digitale disposent de la même dynamique. Et c’est bien là que la théorie transhumaniste risque le plus de se trouver prise en défaut. En effet les chercheurs en intelligence artificielle (particulièrement les chercheurs en programmation génétique) ont depuis plusieurs années compris qu’à une représentation particulière d’un problème correspond ce qu’ils appellent un landscape qui influence très fortement les probabilités d’évolution de leurs algorithmes dans une direction plutôt que dans une autre. Un changement de représentation modifie donc le landscape et les probabilités associées. Il en va de même pour le cerveau : un changement de représentation modifie les probabilités d’évolution de l’intelligence résultante dans un sens plutôt que dans un autre. C’est cette divergence liée à la représentation qui fait dire à Rucker et Wolfram que l’univers n’est pas simulable par autre chose que lui-même (voir à ce sujet l’article de Rémi Sussan).
Mais alors quel serait l’évolution d’une représentation digitale de notre cerveau ? Dans le meilleur (et probablement dans la plupart) des cas elle se dégraderait. La capacité de l’intelligence humaine à réaliser le lien entre le passé et le futur, à avoir conscience du corps qui l’abrite, en un mot sa capacité réflexive, est une chose. Maintenir cette capacité, la faire persister dans le temps, en est une tout autre. Nombreuses sont les maladies psychiatriques qui prouvent que l’équilibre sur lequel se tient l’intelligence est fragile.
La dégradation de l’intelligence digitale est donc très probable mais on peut tout aussi bien imaginer une évolution pathologique ou une évolution « méchante », i.e. nuisible à elle-même ou aux autres. La probabilité de cette dernière possibilité est probablement faible, mais en même temps si vous réunissez suffisamment de singes et leur faites assembler des lettres de scrabble pendant suffisamment longtemps, la possibilité de voir apparaitre une séquence de lettre correspondant au texte de la bible est égale à 1…